Before any document reaches me, a dedicated o3 stage reads every claim in the resume and cover letters and checks it against my raw profile, and nothing else.
The design choice I care about is what this stage is not allowed to see. Its instructions are explicit: it does not get the job analysis or the company dossier, only my own history. That blindness is the whole point. A fact-checker that can see the posting will quietly rationalize a stretch, because the posting makes the stretch sound reasonable. Cut off from it, the model has no story to lean on. All it can ask is whether the claim shows up in my profile.
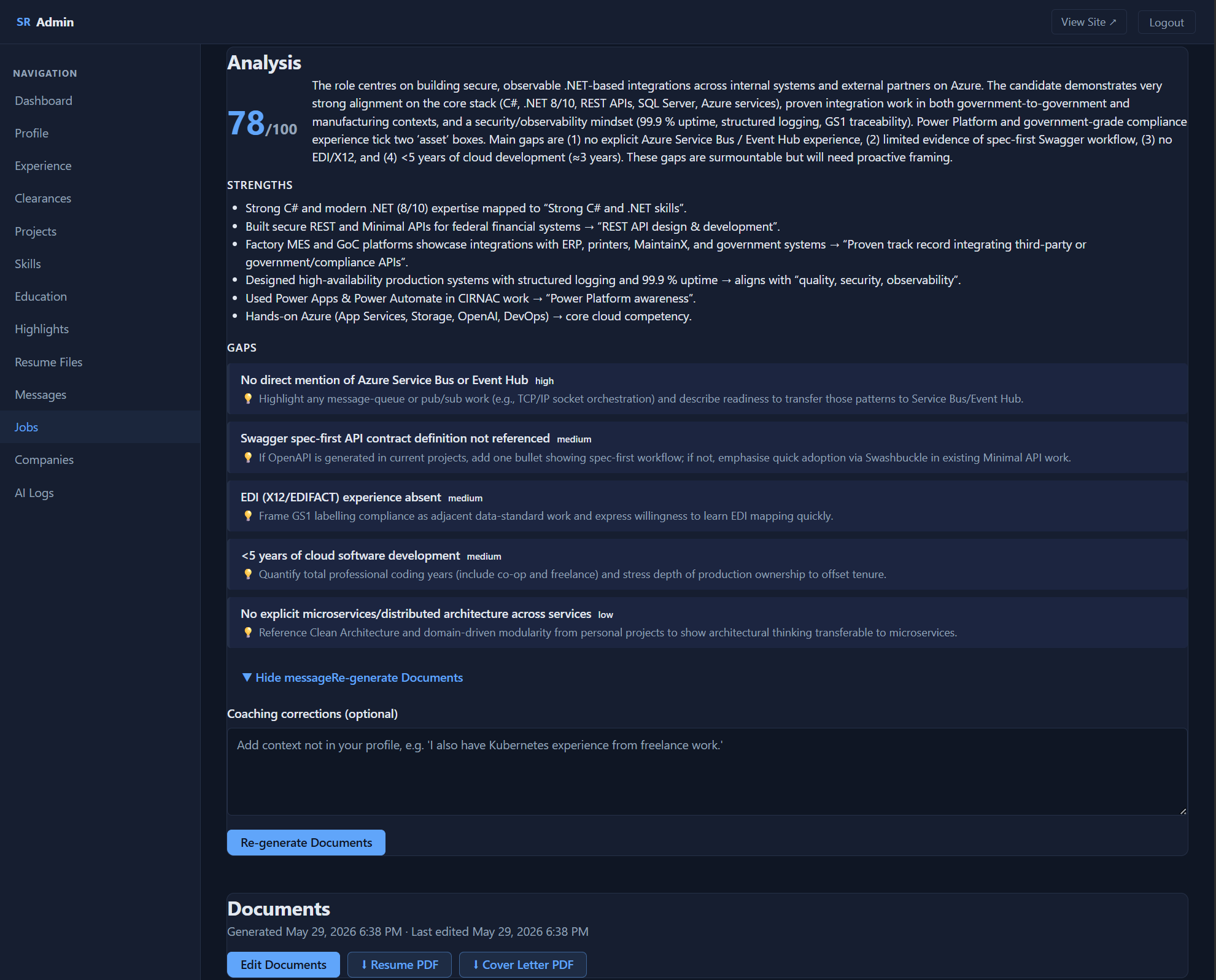
It returns a verdict on each claim, supported, partial, embellished, fabricated, or unverifiable, with the exact profile line that backs it, plus a list of everything that needs revising. A second model then rewrites only the flagged spots; everything else comes back untouched, and if nothing was flagged it never runs at all. The studio shows me which claims are grounded and which are not, so I see the receipts before I send anything.
One honest limit: this catches what the grounding stage flags. If that stage misjudges a claim, the critic won't save me, because there's no second independent judge behind it. It fact-checks every claim against my profile and flags the ungrounded ones. It does not promise zero fabrication.